What this blog covers
Doing projects is perhaps the most effective way to build knowledge and experience in any field, especially disciplines that require extensive practical experience. Since all my projects focus on machine learning, deep learning, and AI in general, I want to share some lessons learned along the way. Some I learned the hard way—wasting tons of time, GPU quota, and frustrating days—so documenting them should help me avoid repeating mistakes and demonstrate my learning journey. Applying Feynman’s technique, let’s go.
Using wrapper models
While working on a project detecting AI- vs human-generated code, I used Stochastic Weight Averaging (SWA). This technique intervenes in the optimizer’s parameter update process, gradually changing model weights more stably with stronger momentum toward old weights. It boosts generalization, prevents overfitting, and controls training stability. More details are available online. The key point: PyTorch provides torch.optim.swa_utils and AveragedModel to eliminate boilerplate. But after wrapping a model with AveragedModel, the model (especially with the transformers library) no longer has the save_pretrained method that Hugging Face provides. The wrapper only exposes the inner model’s methods. You must unwrap the model to access the real method, or checkpoint saving will fail. This small oversight can waste significant training time if you don’t do functional testing before building large training pipelines.
Not unwrapping models enough
Following the note above, sometimes a model is wrapped inside another model that wraps yet another model—a stack of wrappers around a base model. To robustly unwrap the real model and call expected methods (save_pretrained, from_pretrained, etc.), use a while loop to continuously unwrap until no module attribute exists, since outer wrappers access inner models through this attribute:
def _unwrap_model(self, model):
try:
return self.accelerator.unwrap_model(model)
except (AttributeError, TypeError):
# Recursively remove .module wrappers (DataParallel, DDP, etc.)
while hasattr(model, 'module'):
model = model.module
return model
Line by line:
- First, try unwrapping with the high-level API from
accelerate, a fantastic library for distributed training and inference with large models and datasets. This natively gets the inner model without worrying about internals. - If
acceleratorfails, fall back to a manual solution. Conventionally,moduleaccesses the inner model. Use awhileloop to iterate until nomoduleattribute exists, then stop. - Finally, return the actual model inside those wrapper layers.
Saving model with tokenizer
For NLP projects, especially models loaded from Hugging Face, the folder from from_pretrained contains more files than expected. Beyond model.safetensors (the actual weights), several files are indispensable for loading and running training/inference properly. Here’s a typical Hugging Face language model folder:
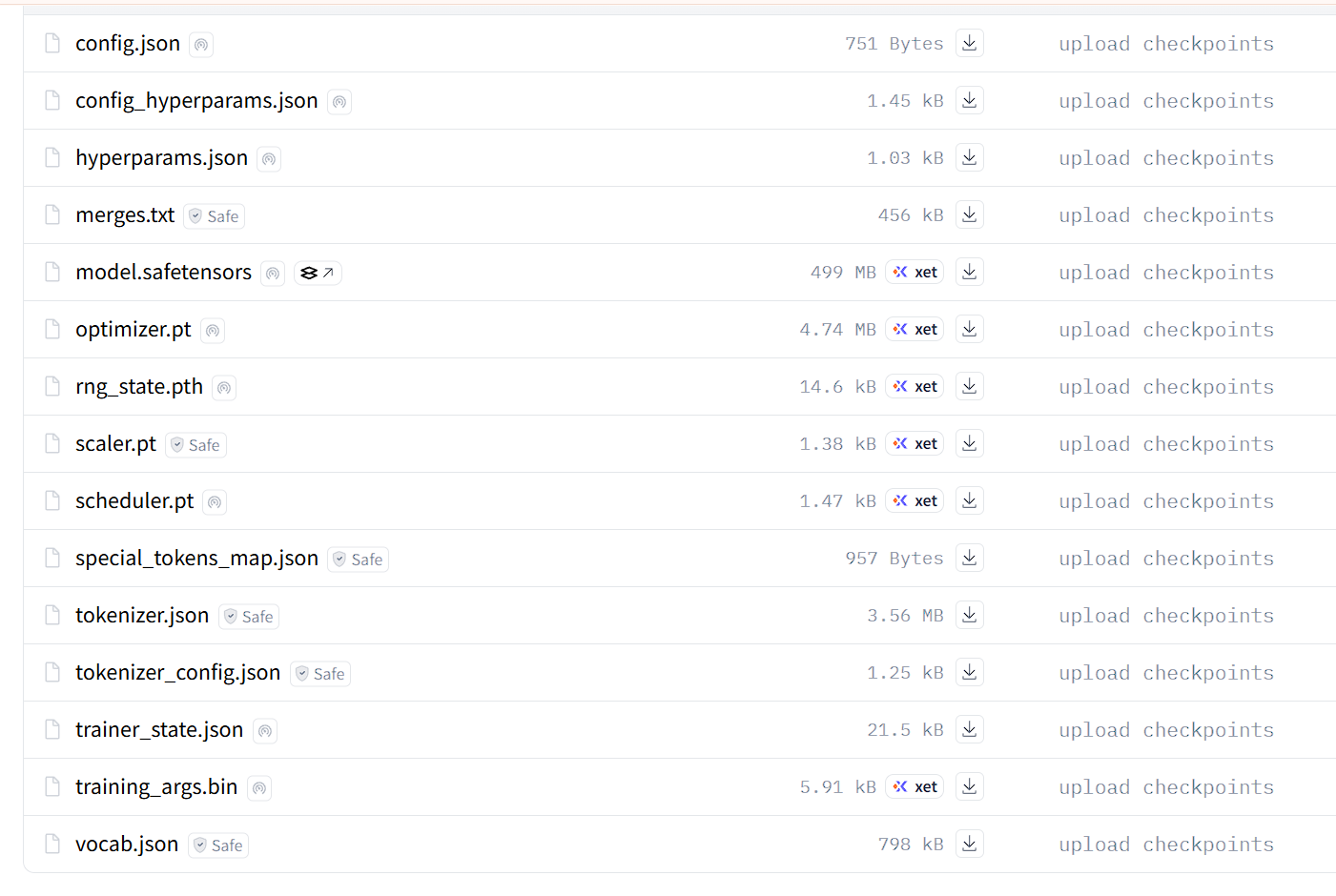
Key file groups:
- Model checkpoint:
model.safetensorscontains all parameters in dictionary format. It’s named “safe” because it stores weights as dictionaries, not execution flow—no architecture knowledge, justself.attention.query.1.weight = torch.Tensor([1, 2, 3, 4, 5, 6]). This prevents unwanted execution on your machine. - Configurations:
config.json,config_hyperparams.json,training_args.bin. These contain architecture info for initialization, hyperparameters, and training arguments for tracking. - Tokenizer:
tokenizer.json,merges.txt,special_tokens_map.json,tokenizer_config.json,vocab.json. These handle tokenization before passing tensors to the model. They’re easy to miss in manual training—you might forget to save the pretrained tokenizer alongside the model, making inference impossible. Always ensure these appear in your checkpoint folders, or your waiting time is mercilessly wasted. - Training State:
optimizer.pt,rng_state.pth,scaler.pt,scheduler.pt. These store optimizer state (Adam stores historical gradients and squares), RNG state (for reproducibility), gradient scaling state (for mixed precision), and scheduler state (for cosine/linear decay). Without them, every resume creates a different scenario because all states reset to initialization. Reproducibility becomes impossible.
Always have degeneration detection in NLP projects
Last semester I worked with Ouro-1.4B, a small looped language model by ByteDance. The model unexpectedly and continually generated degenerate output—total garbage tokens. I proposed several culprits:
- Data type: Kaggle’s T4 GPUs (an older generation) don’t support
bfloat16, the industry standard for LLMs. Usingbfloat16ran without errors, but the documentation said it should error. Silent errors may have occurred. - Novel generation mechanism: Most beginners encounter linear transformers that process text one-way, start to end. This model has loops. The degenerate output might stem from this novelty.
- Small parameter count: At 1.4B parameters, limited capacity affects performance. The model also struggled with the exact answer format in the system prompt—weak instruction following, perhaps from insufficient SFT training.
Since compute isn’t free, waiting hours for garbage output is catastrophically expensive. This hard-learned lesson: a mechanism to detect bad generations is indispensable for NLP projects. Several strong classical string comparison algorithms fit this task perfectly and can be implemented with help from AI assistants like ChatGPT or Claude.
Different backends between interactive and background Kaggle
Kaggle is a friendly companion for free GPU quota (30 hours/week). Notebooks run in two modes: interactive and background sessions. I painfully learned these backend environments differ significantly. The interactive session tolerates runtime errors more benevolently; the background session is prohibitively strict. Once, using protobuf alongside a language model library, a new protobuf version deprecated some modules/classes. The interactive session logged the error but continued running. The background session caught the error immediately and terminated the notebook. The background backend is called Papermill. The error:
AttributeError: 'MessageFactory' object has no attribute 'GetPrototype'